
Introduction
As artificial intelligence becomes increasingly capable of interpreting visual information, image captioning models have emerged as one of the most exciting applications of computer vision and natural language processing. These models can analyze an image and automatically generate a descriptive sentence that explains what is happening within it.
From improving accessibility to enhancing content management systems, image captioning technology is playing a growing role across industries.
What Are Image Captioning Models?
Image captioning models are AI systems designed to convert visual content into human-readable text. Unlike traditional image recognition systems that simply identify objects, image captioning models aim to understand the relationships between objects, actions, and contexts within an image.
For example, instead of merely identifying a dog and a ball, an image captioning model may generate a caption such as “A dog is running across a field while chasing a ball.” This ability to create meaningful descriptions makes the technology particularly valuable for applications that require both visual understanding and language generation.
How Image Captioning Models Work
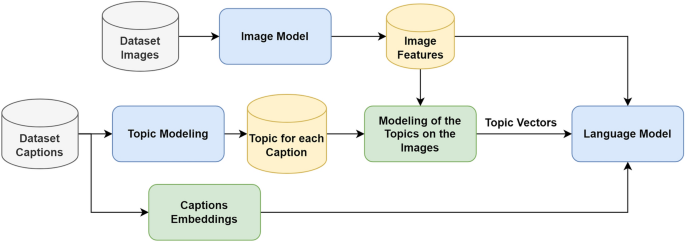
Image captioning combines two major areas of artificial intelligence:
1. Computer Vision
The first step involves analyzing the image itself. A computer vision model extracts visual features such as objects, colors, shapes, backgrounds, and spatial relationships. Modern systems often use deep learning architectures to identify important details within an image.
2. Natural Language Generation
Once the visual information is extracted, a language model converts those visual features into coherent text. The model determines which objects are present, what actions are taking place, and how those elements relate to one another before generating a natural-sounding caption.
By combining visual analysis with language generation, image captioning models create descriptions that closely resemble human observations.
Key Components of an Image Captioning System
Several components work together to produce accurate captions:
1. Image Encoder
The encoder processes the image and transforms visual data into numerical representations that AI models can understand.
2. Feature Extraction
The system identifies relevant elements such as people, objects, environments, and actions within the image.
3. Language Decoder
The decoder generates text based on the extracted visual features, producing a sentence that accurately describes the scene.
4. Attention Mechanism
Modern image captioning models often use attention mechanisms that help the AI focus on important areas of an image while generating different parts of a caption.
Common Applications
Image captioning technology has a wide range of practical uses across industries.
1. Accessibility
One of the most impactful applications is assisting visually impaired users by automatically describing images on websites, social media platforms, and digital documents.
2. Content Management
Organizations use image captioning to automatically tag and categorize large image libraries, making content easier to search and organize.
3. E-Commerce
Online retailers can generate product descriptions from images, improving catalog management and customer experiences.
4. Healthcare
Medical imaging systems can use image captioning techniques to assist health care professionals in summarizing visual findings and documenting observations.
Conclusion
Image captioning models represent a powerful intersection of computer vision and natural language processing. By transforming images into meaningful textual descriptions, these systems enable greater accessibility, streamline content management, and unlock new possibilities for AI-powered applications.
As multimodal AI continues to advance, image captioning models are expected to become even more accurate, context-aware, and valuable across a wide range of industries.

